Top mass updates from CDF: 2 – the world’s best measurement October 23, 2007
Posted by dorigo in news, physics, science.trackback
Last September the CDF collaboration approved a very precise top mass measurement, obtained from the single-lepton final state of top-antitop decay. The measurement method is called MTM2.5, and the value of top mass is found from 1.7/fb of Run II events collected at the Fermilab Tevatron collider.
Saying that the result (which is discussed below) is just “very precise” is a obtuse understatement, for indeed, it is way more than that: it is the single most precise determination of the top quark mass in the world to date, and it reaches alone the same precision of the world average of a dozen different precise measurements obtained just one year ago!
I have discussed the top quark mass measurement, and several issues connected with top production and decay properties, in several posts in the recent past. Rather than re-discovering the wheel, let me produce here a list of relevant links before we go on to discuss this exciting new measurement.
- I discussed very recently the probability of the different final states of top pair decay. If you want to become able to explain to your grandma how comes that a whooping 45% of them top pairs just yield hadronic jets, while a mere 5% give a pair of electrons or muons, I advise you to read the very simple rule for W branching fractions there .
- Top production, both in pairs and single, is explained here in some detail.
- Some more information on top decay is available, for instance, here .
I think I forgot 95% of the things I have discussed in this blog during the past two years, but I am quite sure it is all reasonably good stuff, so if you feel like, do search and you will find. For instance, this one gives 599 hits…
 Anyway, back to the new star result by CDF. First of all I need to mention that some of the authors of the analysis are among the most dedicated scientists I know in the study of top quarks. Lina Galtieri (right) has been in CDF for 20 years now, and was among the ones that first dug the heavy baby out of its hadronic bed.
Anyway, back to the new star result by CDF. First of all I need to mention that some of the authors of the analysis are among the most dedicated scientists I know in the study of top quarks. Lina Galtieri (right) has been in CDF for 20 years now, and was among the ones that first dug the heavy baby out of its hadronic bed.  Jeremy Lys (left)also has 15 years of service in the experiment to his credit, and has always worked in the study of top quarks. Among others I wish to mention Jason Nielsen (below), who did not participate in Run I but has maturated a lot of experience in CDF and is a highly skilled experimentalist -and a great guy. And then John Freeman, Paul Lujan,
Jeremy Lys (left)also has 15 years of service in the experiment to his credit, and has always worked in the study of top quarks. Among others I wish to mention Jason Nielsen (below), who did not participate in Run I but has maturated a lot of experience in CDF and is a highly skilled experimentalist -and a great guy. And then John Freeman, Paul Lujan,  Pedro Movilla Fernandez, and Igor Volobouev: to them I ask for forgiveness since I have no chance to discuss their achievements here.
Pedro Movilla Fernandez, and Igor Volobouev: to them I ask for forgiveness since I have no chance to discuss their achievements here.
What makes the analysis a success is not just the mix of experience and skill of the above group. Nor the fierce competition from other groups in CDF and outside it. It is the coming together of different refined technologies which are extremely well understood and perfectly accepted today, but which just 15 years ago would make people scream in horror if put in a sentence together with “top search”. Neural networks, global multivariate likelihoods, matrix elements, transfer functions: I cannot help smiling if I think that these things used to be whispered in the trailers by inventive physicists but were considered taboo by most of their colleagues, who would put up an invincible flak at the CDF “Heavy flavor group” meetings whenever those unconventional top searches were presented.
Of course, things changed the day after the top quark was discovered by a standard technique….
Sure, the computing power back then simply was not there. Just one simple thing which has become a standard tool for checking one’s analysis methodology, which is the technique of “pseudoexperiments”, was nearly impossible back then. A pseudoexperiment consist in performing a full simulation of the processes your dataset is made of (top pair production along with all backgrounds), and then mixing them according to the known sample composition in order to obtain a sample resembling as closely as possible, within statistical fluctuations, the characteristics you expect your real data possess. Once you have this “mock dataset” you can apply to it all the black magic you decided to use, and extract a mock top mass measurement from it.
Sure, you learn little from one pseudoexperiment. But from 2000, 5000, 10,000 you learn a LOT! A large pool of pseudoexperiments allows you to investigate all the subtle effects that may impair your measurement, due to the details of your technique as much as to the statistical fluctuations expected in the amount of data you have in your hands. As an example, you get straight out of the box an estimate of the intrinsic bias of your measurement technique: If you simulated a top pair production mechanism with a top mass of 175 GeV (it is just a parameter in the simulation: you specify it and the Monte Carlo takes care of the correct physics) and your 10,000 pseudoexperiments, once passed through your measurement tool, show an average result of 178 GeV and a root-mean-square of 4 GeV, you know immediately that your measurement technique has a bias of 3.0+-0.04 GeV (since the error on the mean is the root mean square divided by the square root of the entries, and thus 4/100=0.04).
You might then go back and simulate three further sets of 1,600 pseudoexperiments with input top masses of 165, 170, 180 GeV. You need less than 10,000 in each case, you reason, because you need to determine the bias with a precision of 0.1 GeV so a statistics 
![M(true) = M(found) - 0.09 \times [M(found)-145] GeV](https://s0.wp.com/latex.php?latex=M%28true%29+%3D+M%28found%29+-+0.09+%5Ctimes+%5BM%28found%29-145%5D+GeV&bg=ffffff&fg=666666&s=0&c=20201002)
Should you then measure 175.25 GeV in your real data, you would just subtract 2.75 GeV, and you would get a corrected measurement of 172.5 GeV!
Pseudoexperiments are the bread-and-butter of today’s experimentalist, but 15 years ago we did not have that much CPU. And so, all those fancy multivariate techniques -of which we were already aware of – were not usable because there was no easy way to keep them under control. One could come in your office and tell you “I know how to discover the top quark! You build a likelihood function with jet energies, and cut on its output: your signal to noise ratio is twice as good as the one you get with an analysis based on straight kinematical cuts”, and you would say, “yeah, fantastic!” and shrug your shoulders. Monte Carlo simulations were not tuned well enough back then, and there was little one could do with computer-intensive methods to convince you that top quarks would end up populating the high-tail of the likelihood distribution.
Now let me discuss briefly the analysis technique used to extract the excellent new result. We are talking about the single lepton final state of top pair decay, the one arising from one hadronically-decaying W boson and one leptonic 

A straightforward selection of data containing one lepton with transverse momentum larger than 20 GeV, four jets with corrected transverse energy above 20 GeV and at least one of them b-tagged by a vertex-finding algorithm, plus missing transverse energy (the unbalance of momentum in the plane transverse to the beam line, which signals the escape of a non-interacting neutrino) above 20 GeV finds a total of 343 events in the data.
Such a sample is already very top-rich, but a further cut increasing the fraction of “good” top decays is done later on. However, let me praise the authors for their principled choice of kinematical selection cuts: the final uncertainty in the measured top mass does not depend appreciably from an optimization of the cuts on leptons and jets – you lose one event, you gain two, but in the end with 1.7/fb of data a few events more or less will not make any difference. So what the heck: let’s just cut everything above 20 GeV!
The mass measurement method designed by the authors consists in constructing a likelihood function evaluating for each top decay event the probability that the observed kinematical quantities are as measured, as a function of the unknown value of the top quark mass, the jet energy scale, and all other unknown quantities defining the kinematics of the decay at parton level. It is a complicated technique involving an effective matrix element and some functional forms describing the probability that a parton of given energy E will manifest itself with the value actually measured, plus of course a phase space over which one has to integrate everything. By integrating on all the possible configurations of the decay and the possible production mechanisms, one obtains a function per each event. That function summarizes the information on the top mass of the studied event as a function of the jet energy scale.
Just for fun, here is the likelihood function:
![]()
I will not go into the details of the likelihood further – just go and read their analysis note if you want to known what each symbol means. What I will do, however, just because it is simply too cool, is to show you the modified W boson propagators that enters in the effective matrix element M in the formula above. They are derived by accounting for the tiny approximations connected to assuming zero uncertainty in the measured lepton and jet angles. The probability densities are shown below. Forget what the x and y axes mean: are they cool or not ?


 So far I did not discuss backgrounds, but that does not mean they are negligible. Rather, they are estimated by constructing a Neural Network with the kinematical quantities measured for each event. The output of the NN distinguishes quite well top events from background ones, as shown in the figure on the right – you do not need to read the labels: top is peaking on the right and backgrounds peak on the left of the distribution. The composition of the sample is thus known well, and each background process can be “sized up” in the likelihood distribution of the total sample. That is, each background component is subtracted from the likelihood distribution, according to the expected shape.
So far I did not discuss backgrounds, but that does not mean they are negligible. Rather, they are estimated by constructing a Neural Network with the kinematical quantities measured for each event. The output of the NN distinguishes quite well top events from background ones, as shown in the figure on the right – you do not need to read the labels: top is peaking on the right and backgrounds peak on the left of the distribution. The composition of the sample is thus known well, and each background process can be “sized up” in the likelihood distribution of the total sample. That is, each background component is subtracted from the likelihood distribution, according to the expected shape.
I mentioned before that the sample contains “good” and “bad” top-antitop decays. A “good” top decay in the single lepton final state is defined as one for which the four jets are all directly originated from the hadronization of the four final-state quarks (two from a W and two b-quarks). These events allow a top mass to be extracted with more precision, while “bad” top pair decays are those when one hard gluon emitted by initial or final state radiation surpasses in energy one of the four quarks, thereby spoiling the reconstruction kinematics. The authors found that by cutting on the output of their likelihood they could reduce almost entirely the “bad” events, strongly increasing the power of the measurement.
What to do with the resulting likelihood distribution ? It is scanned as a function of the unknown value of the top mass: for each top mass value, the data provide a likelihood as a function of the jet energy scale. One thus extracts a two-dimensional distribution in top mass and jet energy scale, which peaks at the measured mass.
And what about pseudoexperiments ? Of course, they are crucial, since the method is far from straightforward, as I believe I have convinced the three readers who have survived up to this point. In the end, one needs to estimate the bias of the measurement method. Pseudoesperiments provide it, as shown in the plot below: for many values of input top mass (the quantity on the x axis), the difference between measured and input value is shown by points with error bars. It is clear that the method has a constant bias, which just needs to be added back to the measurement found in the real data.

I do not know about you, but I feel it is due time to disclose the final result of this exceptionally precise technique:

The plot below shows the reconstructed top mass value corresponding to the maximum value of the event likelihood. In blue is the top contribution, in red the background, and the experimental data is shown by the points with error bars.

At the end of this long post, what is left is to discuss systematic uncertainties: please find a very good account of all the details I have glossed over in the very complete web site of the analysis. They are quite small, however, and not by chance: the smallness of systematic uncertainties is in fact one of the strong points of the analysis methodology: it is so by design.
So cheers with good-old CDF, the longest-lasting experiment in the history of physics!
Comments
Sorry comments are closed for this entry

Wow, thanks!
UW Kea… How are your studies on particle masses going ? Are we determining them with too good precision already ? 😉
Cheers,
T.
This is good enough to disagree with the Rosen estimate (but not by much, really). That’s impressive.
Hmm Kea, if Rosen’s estimate is 163.6 GeV, then yes, the disagreement is now at 9.1+-2.1 GeV, or about 5.3+-1.2%. I think the world average of present measurements will be soon determined to be around 171.5 with 1.5 GeV uncertainty (I am just throwing a number off the top of my head, but it can’t be far from that), which will be five-sigma away…
Cheers,
T.
What is Rosen’s estimate?
No, his latest estimate was 177 GeV. Carl, do you have the reference handy?
Wait! Here it is: Mod. Phys. Lett. A 22, 4 (2007) 283-288
Andrea, Rosen’s estimate, as far as I know, derives from a simple formula which attempts to predict all quark and lepton masses from their charges and an integer quantum number, something like , where
, where 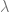 is the root of an equation involving an integer quantum number (0,1,2,3). The formula seems to predict all masses within 1% accuracy…
is the root of an equation involving an integer quantum number (0,1,2,3). The formula seems to predict all masses within 1% accuracy…
I am probably outdated on this however, since my reference is a 1994 book. Surely kea’s reference is better!
Cheers,
T.
I see. Very interesting.
It reminds me of “the strange formula of Dr.Koide”:
http://en.wikipedia.org/wiki/Koide_formula
http://www.arxiv.org/abs/hep-ph/0505220
(I guess that you are already aware of that, since the author of the latter paper happens to be one of your most frequent commenters:))
hep-ph/0505220 😀 The other coauthor, Gsponer, and myself had exchanged email from time to time, and we found a good opportunity to collaborate in this one. With some success, at least creating awareness of the formula and getting some citations.
About G. Rosen, I am not sure what to do, SPIRES gives a series of papers where the estimate changes, but on other hand, as you say, it reminds one of the 45 degrees of Koide formula.
See here. Mass of Top Quark calculated in 2005
http://quantoken.blogspot.com/2005/03/mass-of-top-quark-calculated.html